Pixiv 的动图机制很奇怪,并不是 GIF 或者其他动画格式,而是要求画师将动图的每一帧一帧都上传。
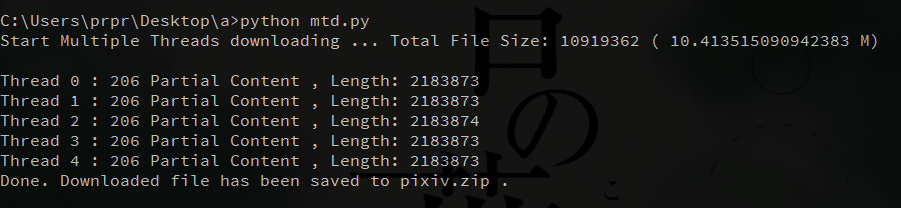
这点从 P 站的 network 里可以看出来,206 分批次下载了一个 zip 包。

然而直接访问这个压缩包却返回 403 Forbidden,看来是服务器加了判断 Referer 的防盗链。然而并没啥卵用,看一下 network 里的 Referer,只要是 pixiv.net 都没关系。遂 wget 之:
$ wget –referer=‘http://www.pixiv.net/’ http://i4.pixiv.net/img-zip-ugoira/img/2015/01/01/04/51/40/47905591_ugoira600x600.zip
顺利下载完毕~压缩包里就是一帧一帧的图片啦,之后用工具处理下就好了。
本来是应该这样就完事了的,但是由于窝突(nao)发奇(chou)想,想用 Python 来实现,顺带用下 urllib,为以后写爬虫做准备。
想得轻松,实现的时候却遇到了不少坑。首先是对 Python 语法的不熟悉,有时候写几句就要去看看文档,简直酸爽。不过 Python 语法并不难,基础的多写一点就记牢了。
还有一个坑是 Python2 和 Python3 的兼容性问题。最开始写的 import urllib2 报错窝还莫名其妙呢,原来是 Python3 后将其并入 urllib 中的一个 module,urllib.request 中了。
其他还有写文件,多线程的各种坑,具体就不说了吧 (´°̥̥̥̥̥̥̥̥ω°̥̥̥̥̥̥̥̥`)
不过确实不难,多查查文档,查查 StackOverflow 一般都可以得到答案。于是跌跌撞撞写出了如下脚本:
import urllib.request import shutil from multiprocessing import Pool from multiprocessing.dummy import Pool as ThreadPool # url as string, header as string, threads as integer def download(url, header, threads): req_list = [] # Get Total File Size fsize_req = urllib.request.Request(url) fsize_req.add_header(‘Referer’, header) total_size = int(urllib.request.urlopen(fsize_req).getheader(‘Content-Length’)) block_size = total_size / threads downloaded = 0 for i in range(threads): request = urllib.request.Request(url) request.add_header(‘Referer’, header) header_range = (downloaded,downloaded + block_size ) downloaded = downloaded + block_size request.add_header(‘Range’,‘bytes=%d-%d’ % header_range) req_list.append(request) path = r’pixiv.zip’ pool = ThreadPool(2) # Here Start Multiple Threads download response_list = pool.map(urllib.request.urlopen, req_list) pool.close() pool.join() print(‘Start Multiple Threads downloading … Total File Size:’, total_size, ‘(’, total_size/1024/1024.0,‘M)’) f = open(path, ‘wb’) out_file = open(path, ‘wb’) for i in range(threads): print(‘Thread’,i,‘:’,response_list[i].status, response_list[i].reason,‘, Length:’,response_list[i].getheader(‘Content-Length’)) # Concatenate these file blocks ino one under path shutil.copyfileobj(response_list[i], out_file) print(‘Done. Downloaded file has been saved to’,path,‘.’)
只是封装了个函数而已(因为还不会类 qwq),参数如下:
download(url, referer, threads)
其中 URL 是需要下载的文件 URL,Referer 是 header 中的 Referer,threads 是线程数。理论上通用其他情况。
然而这个破脚本还有很多不足之处,比如说 proxy 配置还没写好(没时间了),还有可能因为网络中断而下载不完之类的,似乎多线程也不是很完美,总之先这样吧~下星期再完善。
欢迎大触提建议/吊打 qwq